The National Science Foundation Office of Polar Programs (NSF OPP) mandates that metadata, full datasets, and derived data products be stored in a long-lived and publicly accessible archive.
To meet these requirements, the Arctic Data Center was established with NSF funding, serving as this archive specifically for the Arctic Sciences Section (ARC) data and metadata. NSF Dear Colleague Letter #22106 outlines specific requirements from the Office of Polar Programs.

Who Must Submit?
The principal investigator from any NSF OPP funded project is required to submit and publish all relevant metadata and data onto a publicly accessible archive.
Data from ARC-supported scientific research should be deposited in long-lived and publicly-available archives appropriate for the specific type of data collected (by default, the NSF-supported Arctic Data Center or others where appropriate). Metadata for projects, regardless of where they are archived, should be submitted to the Arctic Data Center for centralized access and discoverability.

For all ARC supported projects, see the NSF Data, Code, and Sample Management Policy, which includes the following conditions:
- Metadata files, final data sets, derived data products, physical samples, and relevant software/code must be deposited in a long-lived and publicly accessible archive.
- Samples, data, and associated code must be archived within two years of collection/creation or by the end of the award, whichever comes first, unless required sooner by a particular program or award condition.
- Data management plans that rely on self-publication on personal, lab, or university websites/servers/archives in lieu of appropriate repositories are noncompliant.
For all ARC supported Arctic Observing Network (AON) projects, NSF also requires:
- Real-time data must be made publicly available immediately. If there is any question about what constitutes real-time data, please contact the appropriate NSF Program Officer.
- All data must be submitted to a national data center or another long-lived publicly accessible archive within 6 months of collection, and be fully quality controlled.
- All data sets and derived data products must be accompanied by a metadata profile and full documentation that allows the data to be properly interpreted and used by other researchers.
For sensitive social science data:
-
NSF policies include special exceptions for Arctic Social Sciences (ASSP) awards and other awards that contain sensitive data, including human subjects data and data that are governed by an Institutional Review Board (IRB) policy. These special conditions exist for sharing social science data that are ethically or legally sensitive or at risk of decontextualization.
- If you are unfamiliar with the IRB, the Arctic Data Center has a set of resources which can help serve as a guide to navigate the application process and plans for data post collection.
- In these cases, NSF has requested that a metadata record be created to document non-sensitive aspects of the project and data, including the title, contact information for the dataset creators and contacts, and an abstract and methods description summarizing the data collection methodologies that does not include any sensitive information or data.
-
Please let us know when submitting your record that your data contains sensitive information so that we can adjust our review process accordingly.
- The Arctic Data Center has data tags found early in the data submissions process which serve as a guide for how to proceed. Each data tag indicates the level of sensitivity and/or restriction of the data.
- Please contact your NSF Program Manager if you have questions about what to submit or what is required for any particular award.
Please write to support@arcticdata.io with any questions or for clarifications, and we will help to clarify these policies to the best of our ability. Ultimately, NSF makes the final policy decisions on these data submissions.
Organizing Your Data
Each research project should be organized into data packages that contain all relevant data and metadata from that project or sub-project. Multiple data packages may be associated with a single research project, such as different sampling sites or seasons. The Arctic Data Center provides tools to create data portals that allow related data packages to be discovered together.
What is a Data Package?
Data packages on the Arctic Data Center are simply defined as a collection of related data and metadata files. Each data package should contain, when possible, all of the relevant data and metadata from a specific research project (or sub-project/project component).
Depending on the size of a research project, multiple data packages may be associated with a single research project.
- For example, if a research project consists of field sampling at several distinct sites or over several distinct sampling seasons, each site/season may have its own unique data package.
- When submitting to the Arctic Data Center, it is up to the best judgment of the submitting researcher how their research should be organized.
- If multiple data packages are needed for a research project, they can be made by individually going through the Arctic Data Center website submission tool for each subset.
- After submitting multiple data packages, a data portal can be created to allow the related data packages to be discovered together.
File Guidelines
All of the observations belonging to one type should go in ONE file unless there’s a compelling reason to do otherwise.
You should consider splitting your data into multiple files only in the following cases:
- The data are too big (e.g., > 1 GB) so segmenting them makes access or upload more convenient.
- The data are collected incrementally so new files will need to be added monthly or annually.
Click the following buttons to learn about file content, formatting, and metadata
File Content

An example of tidy data for optimal reproducibility:

Illustration from the Openscapes blog Tidy Data for reproducibility, efficiency, and collaboration by Julia Lowndes and Allison Horst
File Format

For projects planning to submit to the Arctic Data Center, we strongly advise incorporating plans for using open formats in the project’s early stages (e.g., in the data management plan).
If your data is in proprietary formats like Excel or MATLAB (<v7.3), plan to convert them into open formats before submitting. If you must submit proprietary files, the Center may request an explanation and will ask for an open-source alternative that can read the files.
Open source file format recommendations:
- Tabular data: CSV or TXT
- Image files: PNG, JPEG, or TIFF
- GIS files: ESRI shapefiles or GeoJSON
- MATLAB/matrix-based programs: NetCDF
- NetCDF is recommended for archiving large numbers of uniform matrices or arrays. More info here.
For transparency and automated parsing, upload files individually and avoid zipped archives.
- Zipped archives make it difficult to view specific files and complicate metadata assignment. Exceptions include formats that require multiple files together (e.g., shapefiles).
Metadata

Metadata should fully document a project so another scientist can reuse it without external guidance. Typical metadata components include:
- A descriptive title including topic, location, dates, and scale.
- An abstract summarizing the data package’s contents and purpose.
- Funding information (e.g., NSF award number).
- A list of people/organizations involved, including creator(s) and contact(s). See Identification Guidelines.
- Complete records of field/lab sampling times and locations.
- Taxonomic coverage (if applicable).
- Descriptions of field/lab methods.
- Descriptions of hardware/software used (including versions).
- Full attribute/variable descriptions.
- Quality control procedures.
- Explanations for important methodological choices.
Additional guidance for specific metadata cases is provided below in your full document.
Tabular and Spatial Data
Submitted metadata should contain detailed metadata for every attribute collected.
Attributes in tabular data (e.g. age, sex, length of fish encoded in a CSV file) are often referred to as variables and are arranged in either columns or rows. Note that storage of data in a long versus wide format will allow for more succinct metadata (see File Organization Guidelines).
In spatial vector data (e.g. lake features encoded in a shapefile), attributes describe a feature characteristic (e.g. lake area). In spatial raster data, the attribute of interest is encoded as a cell value for a given location (e.g. Advanced Very High Resolution Radiometer Sea Surface Temperature (AVHRR SST) encoded in a NetCDF matrix).
The following components are needed to describe each attribute:
- A name (often the column or row header in the file). Like file names, only letters, numbers, hyphens (“-“), and underscores (“_”) should be used in attribute names. Always avoid using spaces and specialized ASCII characters when naming attributes.
- A complete definition. The definition should fully clarify the measurement to a broad scientific audience. For example, a definition like “%C” may always be interpreted within a certain discipline in a uniform way. However, it might always be interpreted within another certain discipline in a different uniform way. A full technical definition such as “percent soil carbon by dry soil mass” helps to limit possible confusion.
- Any missing value codes along with explanations for those codes (e.g.: “-999 = instrument malfunction”, “NA = site not found”).
- For all numeric data, unit information is needed (e.g.: meters, kelvin, etc.). If your unit is not found in the standard unit list, please select “Other / None” and we will change this to the appropriate custom unit.
- For all date-time data, a date-time format is needed (e.g.: “YYYY-MM-DD”).
- For all spatial data, the spatial reference system details are needed.
- For text data, full descriptions for all patterns/codes are needed if the text is constrained to a list of patterns or codes (e.g. a phone number would be constrained to a certain pattern and abbreviations for site locations may be constrained to a list of codes).

Software
For data packages with software (including models), submitted metadata should contain the following components, among others:
- Instructions on how to use the software.
- Version information.
- Licensing information.
- A list of software/hardware used in development.
- A list of software/hardware dependencies needed to run the software.
- Information detailing source data for models.
- Any mathematical/physical explanations needed to understand models.
- Any methods used to evaluate models.

Guidelines for Large Data Packages
The Arctic Data Center does not have data package or file size limitations for NSF-funded projects. Many multi-terabyte data packages have been archived on the Arctic Data Center. In most cases, all data and metadata relevant to each project should be archived regardless of total file size (note, non-NSF funded projects may be subject to a one-time processing fee depending on the total data package size). The Arctic Data Center website can handle the upload of multiple large files simultaneously. However, researchers with slow internet connections or those that experience any trouble uploading any file through the website should contact the Arctic Data Center support team at support@arcticdata.io. The Arctic Data Center support team has many options to upload large data packages when connection speed is limited or files are exceptionally large.
Click on the buttons below to learn about guidelines for a large number of files and large models
When a dataset has a large number of files (around 1000+ files), uploading these files through our web editor can take a very long time. In this case, we ask that you email our support team so that we can guide you on uploading the files directly to our server. We will provide you with credentials to remotely connect and upload your data directly to our server. These files will be stored in a web-accessible location on our server that will be referenced in your data package.
We will then ask you to submit a data package on our web editor without adding any files. We will ask you to provide the file path and file naming convention used for your dataset, a brief 1-2 sentence description for each different file type, and attribute definitions and units when applicable.
Computational models are growing in their capacity to consume large datasets and create complex, fine-scale outputs that sometimes reach multiple terabytes in size. Although in theory model output can be regenerated by re-running the model, doing so may require access to high-performance supercomputing, making reproduction costly and impractical.
Researchers interested in archiving large model outputs are encouraged to contact Arctic Data Center staff well in advance of publication or reporting deadlines with a statement on the model output’s value to researchers and the community, how the output could be re-used by others, and an estimation of how long you believe the model outputs will be useful. Our team will provide guidance on our storage capacity, file structuring and chunking strategies, and data transfer plan. The following summarizes the new ADC policy outlining the archival of large model outputs. The full policy can be found here.
- Consider storing large model output datasets (e.g., roughly larger than 0.5 TB) if they are valuable for analytical reuse to Arctic researchers and the broader Arctic community
- Continue to store the model code itself, along with documentation and sample data sufficient to understand and regenerate the output
- Re-evaluate the decision to store each large model output dataset once every five years, with input from the Arctic research community on whether the data are sufficiently valuable and sufficiently accessed to justify continued storage and distribution
Once archived, large model output datasets will include model code, documentation, example inputs and output files, and full model outputs. These datasets will undergo a review every 5 years to reassess their continued utility. During the review, we will contact the dataset creators for discussion, and may reach out to additional experts in the field to function as advisors. If the full model output is determined to have diminished utility, they will be removed. However, code, documentation, and example input/output files will remain in the archived dataset to ensure reproducibility.
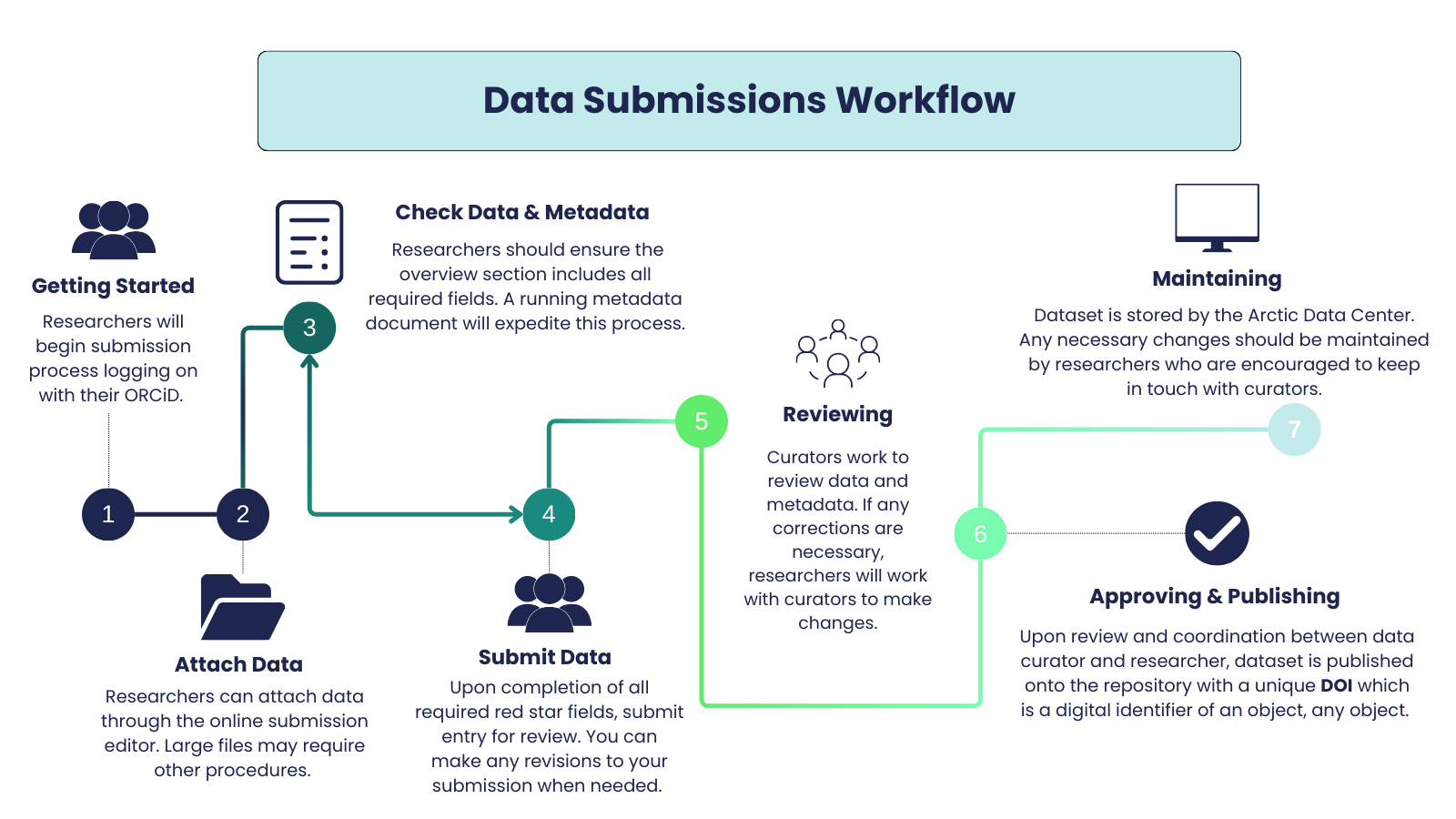
The Submission Process
The following sections provide details on accessing the Arctic Data Center using an ORCID account, the licensing requirements for distributing data and metadata, the publication process, and the currently available tools for submission. The general submission workflow can be reviewed below.
Identification Guidelines
The Arctic Data Center requires submitters to have ORCID iDs for proper identification and attribution to each data package. ORCiDs are not required for all associated parties (contacts, additional creators, etc.), but are strongly encouraged, especially for the primary creator. Only individuals with ORCiDs can be granted editing access to data packages. Therefore, we advise researchers to register and record ORCID iDs for each individual involved with a project during the initial stages of project development.
Licensing and Data Distribution
All data and metadata will be released under either the CC-0 Public Domain Dedication or the Creative Commons Attribution 4.0 International License, with the potential exception of social science data that have certain sensitivities related to privacy or confidentiality. In cases where legal (e.g., contractual) or ethical (e.g., human subjects) restrictions to data sharing exist, requests to restrict data publication must be requested in advance and in writing and are subject to the approval of the NSF, who will ensure compliance with all federal, university, and Institutional Review Board (IRB) policies on the use of restricted data.
As a repository dedicated to helping researchers increase collaboration and the pace of science, the Arctic Data Center needs certain rights to copy, store, and redistribute data and metadata. By uploading data, metadata, and any other content, users warrant that they own any rights to the content and are authorized to do so under copyright or any other right that might pertain to the content. Data and facts themselves are not covered under copyright in the US and most countries, since facts in and of themselves are not eligible for copyright. That said, some associated metadata and some particular compilations of data could potentially be covered by copyright in some jurisdictions.
By uploading content, users grant the Arctic Data Center repository and the University of California at Santa Barbara (UCSB) all rights needed to copy, store, redistribute, and share data, metadata, and any other content. By marking content as publicly available, users grant the Arctic Data Center repository, UCSB, and any other users the right to copy the content and redistribute it to the public without restriction under the terms of the CC-0 Public Domain Dedication or the Creative Commons Attribution 4.0 International License, depending on which license users choose at the time of upload.

Publication
The Arctic Data Center provides a long-lived and publicly accessible system that is free for other researchers to obtain data and metadata files. Complete submissions to the Center must meet the requirements set by the NSF OPP, which require that metadata files, full data sets, and derived data products be deposited in a long-lived and publicly accessible archive.
Submission of data packages to the Arctic Data Center is free for all NSF-funded projects. Data packages from projects not funded by NSF are permitted to submit to the Center but may be subject to a one-time processing fee, depending on the size and processing needs of the data package. Additionally, to be published on the Arctic Data Center, data packages from projects not funded by NSF should cover relevant Arctic science research. Contact us with any questions on these submissions. Please note that submissions of NSF-funded data packages are prioritized in our processing queue.
- Researchers will submit data to the Arctic Data Center through the Arctic Data Center website (see Submission Support if needed).
- The Center’s support and curation team will review the initial data submission to check for any issues that may need to be resolved as quickly as possible. Any extensive corrections might delay processing time, therefore, it is critical researchers communicate early and diligently.
- All communication between the Center’s team and submitter’s ORCID iD will be primarily corresponded via email from support@arcticdata.io to the email address registered with the submitter’s ORCID iD.
- We advise researchers to submit data packages well before deadlines.
- For most ARC-funded projects, all data and metadata submissions are due within two years of collection or before the end of the award, whichever comes first. The data submission deadline is stricter for Arctic Observing Network (AON) projects, with real-time data to be made publicly available immediately and all data required to be fully quality controlled and submitted within 6 months of collection. Please see below for the submission requirement exceptions for sensitive social science data.
The publishing process can take around 2 weeks for datasets with a few files, and it may be longer depending on the complexity and size of the dataset. Long processing times typically occur due to incomplete metadata, poorly organized files, or lack of responsiveness to follow-up emails. Compliance with the guidelines detailed here should ensure quick processing times. Well-organized and complete data packages can potentially be published within one business day. After the review process, each data package will be given a unique Digital Object Identifier (DOI) registered with DataCite using the EZID service, and is discoverable through various data citation networks, including DataONE.
Depending on the complexity of the data package and the quality of the initial submission, the review process can take anywhere from a few hours to several weeks. Long processing times generally occur when initial submissions have incomplete metadata and/or poorly organized files and/or the submitter is not responsive to follow-up emails. Compliance with the guidelines detailed here should ensure quick processing times. Well organized and complete data packages can potentially be published within one business day. After the review process, each data package will be given a unique Digital Object Identifier (DOI) that will assist with attribution and discovery. The DOI is registered with DataCite using the EZID service, and will be discoverable through multiple data citation networks, including DataONE and others.
 Once the data package is published with the Arctic Data Center, it can still be edited and updated with new data or metadata. Additionally, the original data and metadata will remain archived and available to anyone who might have cited it. Updates to data and metadata can be made by clicking the green “Edit” button on the website of any data package (researchers will need to log in and have edit access to see the green button).
Once the data package is published with the Arctic Data Center, it can still be edited and updated with new data or metadata. Additionally, the original data and metadata will remain archived and available to anyone who might have cited it. Updates to data and metadata can be made by clicking the green “Edit” button on the website of any data package (researchers will need to log in and have edit access to see the green button).
Each data package DOI represents a unique, immutable version, just like for a journal article. Therefore, any update to a data package qualifies as a new version and therefore requires a new DOI. DOIs and URLs for previous versions of data packages remain active on the Arctic Data Center (i.e., they will continue to resolve to the data set landing page for the specific version they are associated with), but a clear message will appear at the top of the page stating that “A newer version of this data package exists” with a hyperlink to the latest version. With this approach, any past uses of a DOI (such as in a publication) will remain functional and will reference the specific version of the data package that was cited, while pointing researchers to the newest version if one exists.
Submission Tools
The materials from Section 5.5, “Publishing Data from the Web” from our Arctic Data Center training can help guide you through the submission process.
Most researchers submit to the Arctic Data Center through the Arctic Data Center website. However, there are several alternative tools to submit data packages to the Center.
Researchers can also submit data inside an R workflow using the DataONE R package.
Considerations with Submission Tool Editor:
- Our Submission Tool editor has six different sections which focus on the scope of your dataset. Each section will have required information needed to process your dataset. Once submitted you will work with our data curators to ensure all required fields are ready for publication.
- Once your submission is completed you are able to make any changes to the dataset before and after publication.
- We would urge researchers to closely pay attention to the Ethical Research Practices field and describe how and the extent to which data collection procedures followed community standards.
- The CARE Principles serve as an additional guide.
- The Arctic Data Center developed an Ethical Arctic Research Practices Guide. For more information, visit data ethics.
- For further information, visit “Publishing data from the web” reference.
Click on the buttons below for additional submission guidelines
In addition to the web and data tools shown above, the Arctic Data Center provides the ability to access and submit data via the DataONE REST API. This allows the community to use many programming languages to add data and metadata to the repository, search for and access data, and automate any process that might otherwise be highly time consuming. Most useful to groups with repetitive tasks to perform, such as submitting many data files of the same type, the REST API can be a real time saver. For more details, please contact us at support@arcticdata.io. The Arctic Data Center currently encodes science metadata in the Ecological Metadata Language (EML). Packaging information (how metadata files are associated with data files) is currently encoded in resource maps using the Open Archives Initiative Object Reuse and Exchange specification. Please contact support@arcticdata.io for detailed help with programmatically producing these XML-based files.
If, for any reason, support with a submission is needed, contact support@arcticdata.io and an Arctic Data Center support team member will respond promptly.
If you have a large volume of files to submit or the total size of your data is too large to upload via the web form, please first submit your complete data package description (metadata) through the Arctic Data Center website without uploading any data files, and then write to support@arcticdata.io to arrange another method for the data transfer. The support team has multiple options for transferring large amounts of data, including via Google Drive or our SFTP service.
💡
Have questions not answered in this guide? Please see the Frequently Asked Questions section of the Center’s website, or contact support@arcticdata.io and a member of the Arctic Data Center support team will respond promptly.