Highlight: “This course was an incredible opportunity to learn directly from the experts about best practices in scientific computing. It provided comprehensive training on data handling and computing – both training participants in fundamental coding skills and offering a broad survey of emerging trends in scalable computing. I now feel equipped to tackle bigger and broader analyses of the ever-expanding wealth of Arctic data.” – Mackenzie Jewell, PhD student at Oregon State University

The Arctic Data Center (ADC) held the fourth iteration of the popular 4.5-day Scalable and Computationally Reproducible Approaches to Arctic Research training from April 7-11th, 2025 for 19 Arctic researchers from across the globe. Course topics focused on computationally reproducible research in Python, software and techniques for working with large datasets, and best practices for working in cloud computing environments, docker containers, and parallel processing. Lessons were a mix of technical and non-technical, with an emphasis on hands-on activities instead of lecturing when possible.
Day 1
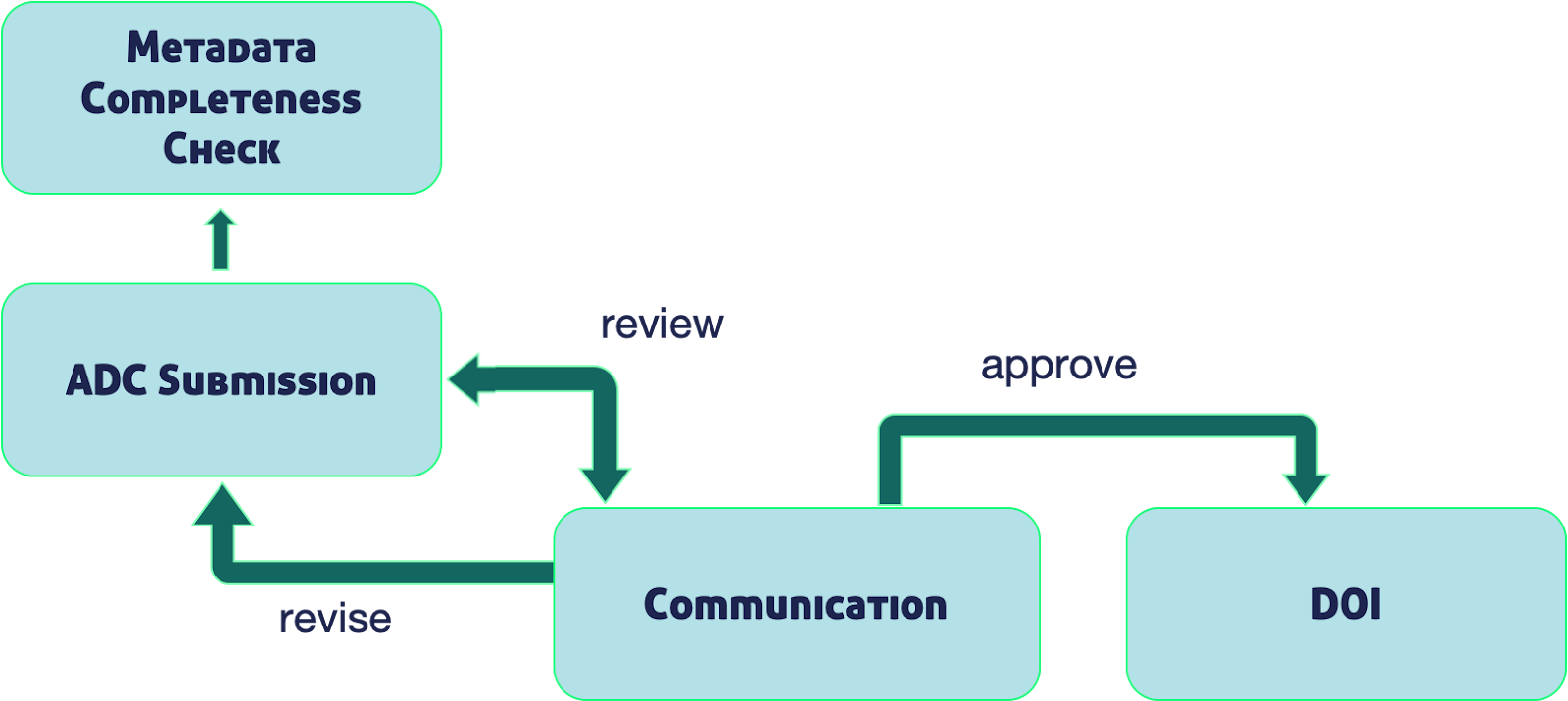
Overview of the data submission process and support services at the Arctic Data Center
The first day of the course began with instructor and participant introductions and an overview of the ADC and how our team can serve the Arctic research community through data archiving, curation support services, our data discovery portal, data visualizations, data rescue, and training and outreach opportunities. This was followed by an introduction to remote computing, manipulating files and directories in virtual environments, containerized computing, and the different types of cloud computing which set the basis for the third lesson, Python programming on clusters. This lesson provided a basic review of using a virtual environment through Visual Studio Code, basic Python syntax and base variable types, using Jupyter notebooks, and creating functions. The afternoon ended with a deep dive into parallel programming using concurrent.futures and Parsl, a practice that helps with computations that are expensive in cpu time and memory. Each day wraps up with a ~30 minute Q&A session that allows participants to get answers to any questions they have before moving on to new material the following day.
Day 2
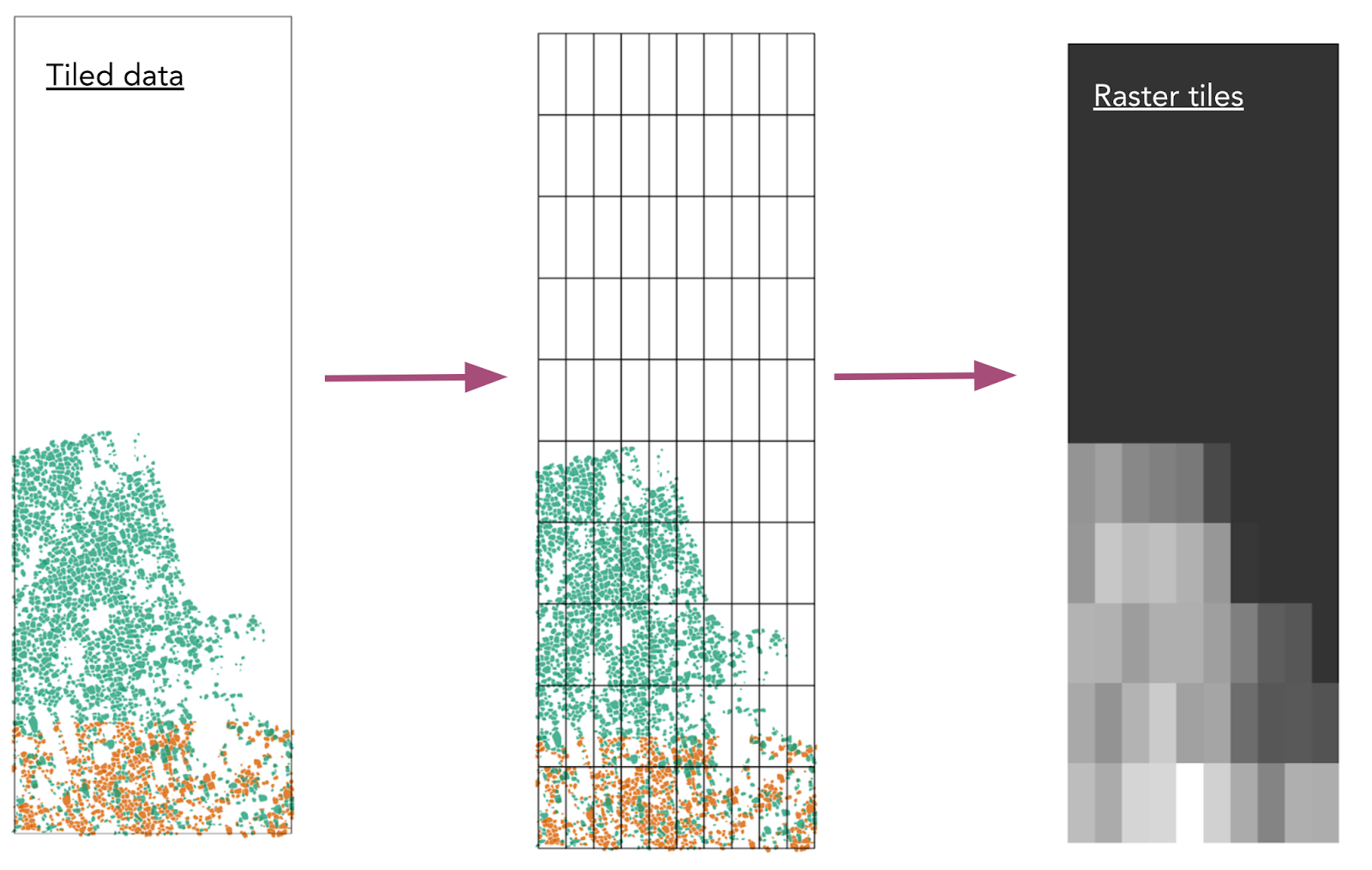
Graphic showing the conversion of original data, to tiled data, to a raster file from the Group Project.
We jumped into the second day with a lesson on data structures and formats for large data, which taught participants about the NetCDF data format and how to use the xarray package to work with NetCDF files. This lesson included short practice exercises that quizzed participants on identifying a dataset’s variables, attributes, and dimensions. The next lesson focused on parallelization using Dask, a library that can scale up code to use your computer’s full capacity or distribute work in a cloud cluster. Participants learned how to connect to an existing cluster and set up their own local cluster. We switched gears after lunch to introduce the 2-day group project, the first section focusing on preprocessing and rasterizing permafrost ice wedge data. For this project, participants broke into groups of 3-4 people and worked together to tile the data into smaller files with regular (non-overlapping) extents, stage them into
GeoPackages, and convert them to rasters. Day two concluded with a non-technical lesson that discussed ethical considerations for scalable computing. Topics included the FAIR (findable, accessible, interoperable, reusable), CARE (collective benefit, authority to control, responsibility, ethics), and FAST (fairness, accountability, sustainability, transparency) principles, resources and practices regarding data ethics at the ADC, and considerations specific to artificial intelligence (AI) research. The lesson ended with a breakout discussion about how the CARE and FAST principles apply to large-scale AI applications and how researchers can ensure they’re conducting research ethically.
Day 3
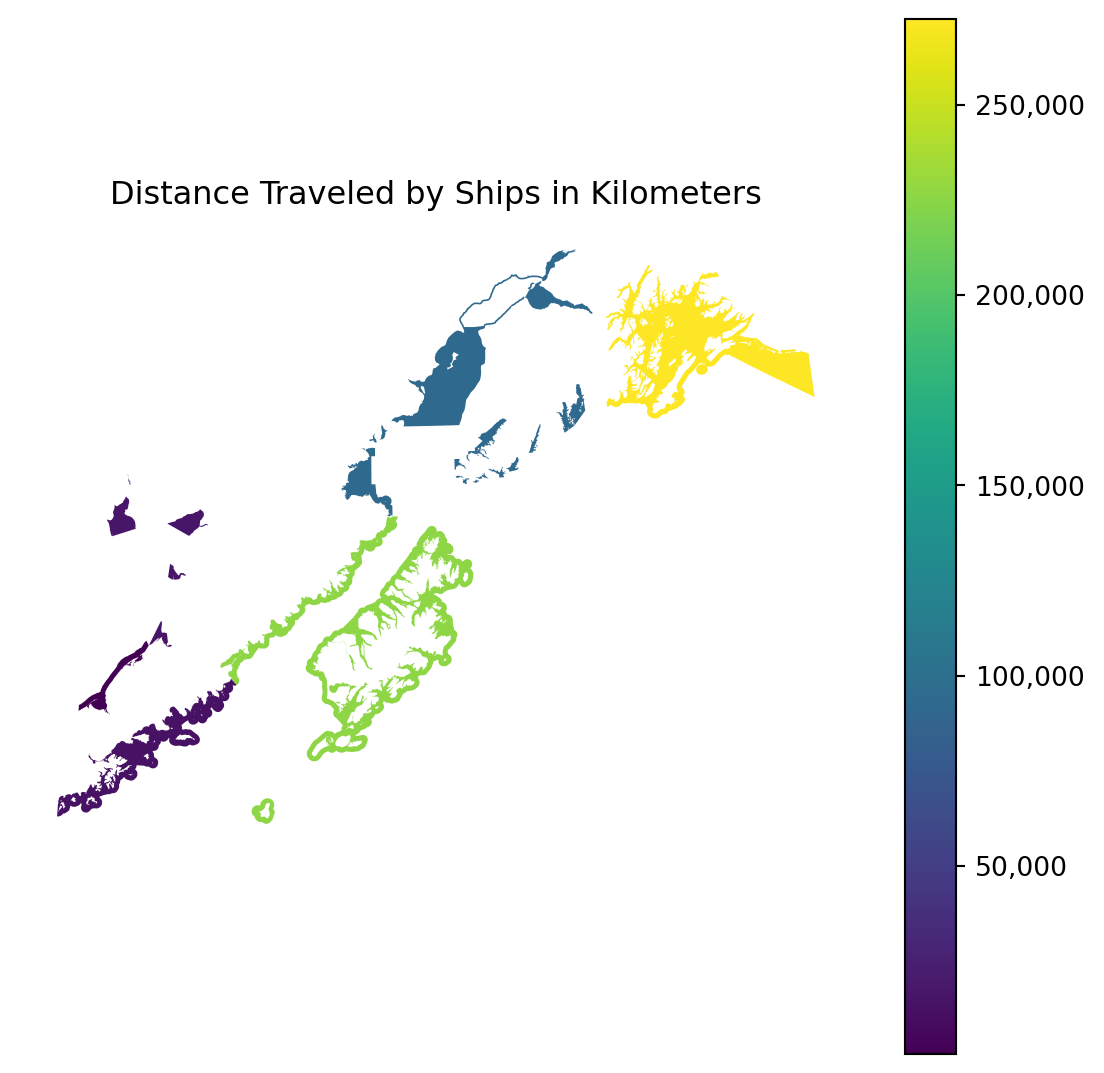
Plotted result from the Spatial and Image Data Using GeoPandas lesson showing distance traveled by ships in a region of Alaska.
The third day of the training was the most technical content-heavy day of the week filled with all technical lessons. We began the day with an introduction to manipulating spatial and image data using Rasterio (raster data) and GeoPandas (vector data). Participants used both vector and raster data together to calculate the total distance traveled by ships within each fishing area using two datasets: the Alaskan commercial salmon fishing statistical areas and North Pacific and Arctic Marine Vessel Traffic datasets. The next lesson focused on using Parquet, DuckDB, and Arrow to solve scaling problems when working with tabular data. This lesson covered the difference between column major and row major data, speed advantages to columnar data storage, and advantages to using Parquet to store columnar data, DuckDB as an in-memory query engine, and using Arrow for faster processing. This was followed by the second part of the group activity, focusing on further processing raster files by resampling them to lower zoom levels for data visualization. The last lesson of the day was an introduction to software design for concurrency, covering topics such as functions as objects, global variables, pure functions, task dependencies, and locks, deadlocks, and race conditions.
Day 4
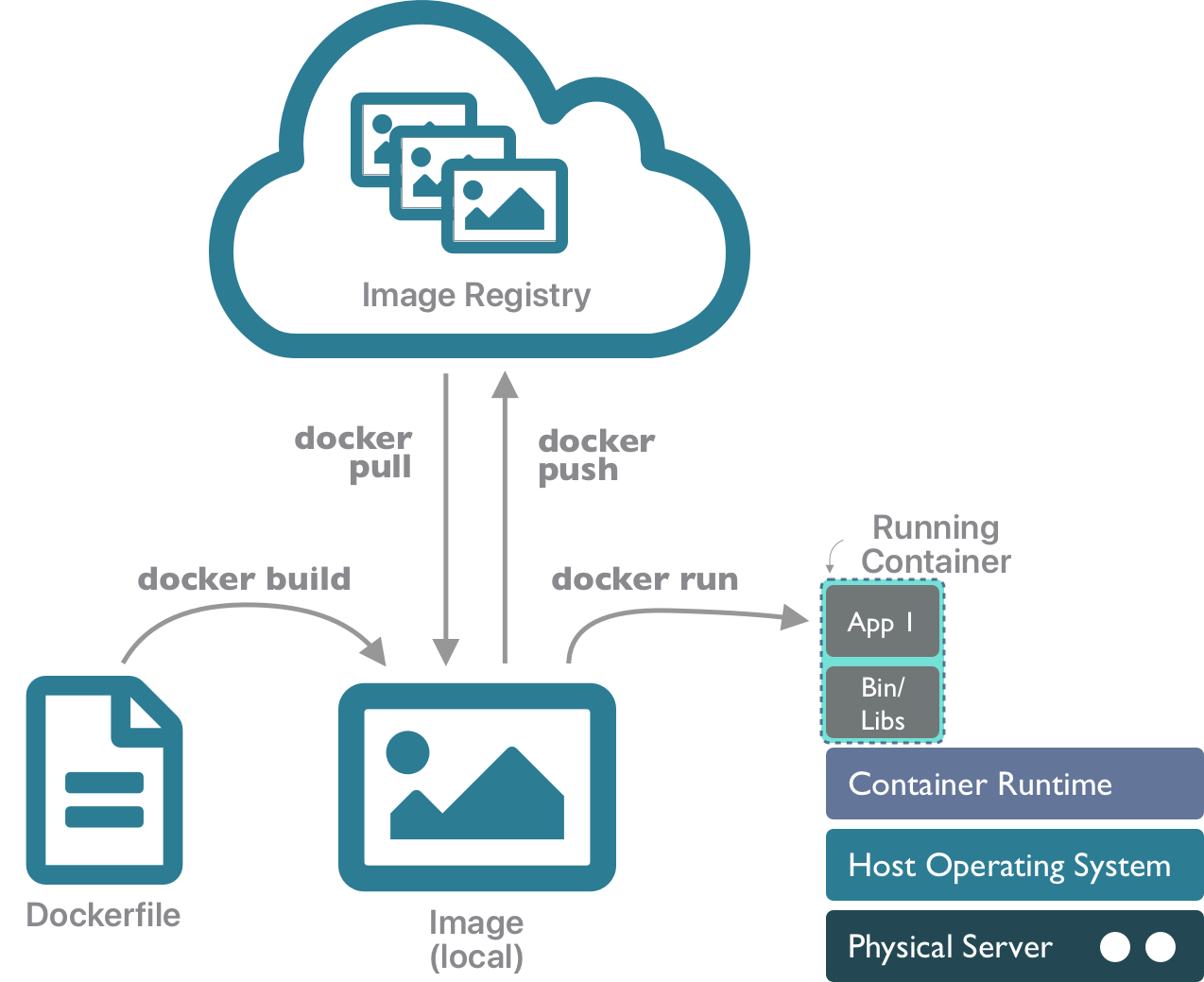
Image of the container lifecycle from the Docker Containers lesson.
After an information-packed Wednesday, we began the last full day of the course with a non-technical lesson focusing on documenting and publishing (large) data to the ADC and other open data archives. Participants learned best practices for what to include in metadata, what a data package consists of, how to plan for large data submission and when to reach out to our support team, and how to efficiently transfer data to the repository depending on size, network speeds, endpoints, and more. You can find more information on our data submission guidelines here. The next lesson included an introduction to the Zarr file format for cloud data storage, how to retrieve and work with a CMIP6 Zarr dataset from Google Cloud Storage, and how to create a Zarr dataset. In particular, this lesson taught participants the differences and similarities between Zarr and NetCDF file formats and when to use each one. The afternoon began with a lesson on Docker containers as a tool to improve computational reproducibility. This lesson taught participants about containers, images, container runtimes, image registries, Dockerfiles, the container lifecycle, and more. Day four concluded with a continuation of the previous software design lesson and provided an overview of Python modules to organize commands that create functions, variables, and other definitions to be reused, Python packages to bundle modules and documentation to make code reusable and shareable, using Python Poetry to manage packages and their dependencies, and how to test functions to ensure they operate with good and bad data.
Day 5
The final day of the course consisted of two summary lessons, one technical lesson on navigating the cloud-scale data landscape, and a shorter non-technical lesson on reproducibility and traceability. The first lesson reviewed some of the processing bottlenecks in large-scale data analysis, recapped the various tools and technologies presented throughout the week and how they all fit together, and discussed cloud-optimized data formats and access patterns. The second lesson provided an overview of dependency management, reproducibility, provenance, and software management and tips to improve data traceability. The course concluded with an anonymous survey to collect feedback on course curriculum and logistics, as well as an open discussion where participants shared verbal feedback that we will incorporate into future course offerings.
Screenshot of an interactive user interface of a workflow build by DataONE from the Reproducibility and Traceability lesson
Firsthand Accounts from Participants
Maria Luisa Rocha:
Based at Brown University in Rhode Island, Maria Luisa Rocha is a researcher studying how Arctic polar lows affect ship safety. Much of her work relies on large climate datasets and running Arctic weather simulations. Reflecting on the course, she noted, “learning best practices for coding and handling large datasets [was most valuable].”
She especially appreciated the introduction to Docker environments which helped her better understand the infrastructure behind the high-performance computing she relies on. Like many other participants, Rocha gained insights into the computational backbone of scientific research and how it can make her work more efficient and reproducible. Moving forward she plans to apply the tools learned to her Arctic weather simulations to help streamline her workflow and make her work easier to share with collaborators and build upon.
Mike Loranty:
Michael Loranty, a Professor of Geography and Director of the Environmental Studies Program at Colgate University, also participated in our course. He’s no stranger to the Arctic Data Center and has previously submitted data, with one of his datasets featured during our Day 2 lesson on Parallelization with Dask.
Reflecting on the experience, Loranty noted, “[This] course helped to further develop my programming skills and orient me within the dynamic landscape of scientific computing.” These new tools and approaches won’t just be applicable to his own research, but will expand the knowledge shared with his students.
The photo below captures Loranty’s students collecting ground truth data for some of their drone and machine learning research.

Credit: Michael Loranty
MacKenzie Jewell:
MacKenzie Jewell, PhD student at Oregon State University, greatly appreciated the course as an early-career researcher. The opportunity to dive into the wide range of new material gave her valuable exposure to practices that she says will fundamentally shape the future of her career.
More specifically, Jewell said, “This course was an incredible opportunity to learn directly from the experts about best practices in scientific computing. It provided comprehensive training on data handling and computing – both training participants in fundamental coding skills and offering a broad survey of emerging trends in scalable computing. I now feel equipped to tackle bigger and broader analyses of the ever-expanding wealth of Arctic data. With the on-site training and take-home open resources, this course has given me the tools to increase the scale and scope of science projects I will conduct throughout my career. It also connected me with a network of other enthusiastic scientists across a broad range of disciplines aiming to address big questions. As an early career scientist, I’m grateful for the Arctic Data Center’s investment in my own career and the broader scientific community by offering this course and providing travel support to those who need it in order to participate.”
Mikhail Schee:
Postdoctoral Fellow Mikhail Schee, from the University of Toronto, attended this course and had the opportunity to participate in the 2024 Cyber2A data science training focused on Artificial Intelligence (AI) and machine learning for Arctic researchers. Both trainings required a solid foundation in programming to attend. Upon reflection, Schee shared: “My experience at the ADC workshops has opened my eyes to the many things I do not know about data science and data management and, crucially, given me the knowledge base I need to continue learning more about these topics.”
Like many other participants, Schee greatly appreciated the emphasis on data management best practices. He spoke to the overall value of the ADC data science trainings for researchers:
”I believe it is incredibly valuable for researchers to be supported in participating in trainings such as those offered by the ADC. While there are certainly resources freely available online to learn the material covered by these workshops, it is invaluable to have knowledgeable experts immediately available to answer questions. Nothing can beat the ability for the instructors to answer the “what if?”s that are just outside the example in the course book.
I found it incredibly helpful to be able to engage with the instructors and other participants both in sessions and in down time. I learned so much more and developed more connections with other researchers at these workshops than any other scientific conference I’ve attended.
The datasets involved in Earth system science are continuing to grow in size and complexity so it is increasingly important for researchers to understand how to work with such datasets effectively and efficiently.”
The variety of technical and non-technical lessons offered during the week-long course allowed participants the opportunity to build a broad and mixed skill set. Schee noted the FAIR and CARE principles will take on a new life in his own work, challenging him to think more critically about the connections between research and the impact it has on communities.
Insights and Reflections from Our Instructors

Openly Accessible Course Materials
The Arctic Data Center’s Scalable Computing course has continuously evolved throughout many years of teaching and is revised based on participant and instructor feedback. The 2025 coursebook is openly available here. Additionally, you can find coursebooks from our previous trainings on our website here, updated after each training concludes.
Written by Nicole Greco and Angie Garcia
Community Engagement & Outreach Coordinators