Finding the Data You Need: Improving search functionality through semantics in the NSF Arctic Data Center

The situations illustrated to the right and many other potential questions provide the motivation behind the Arctic Data Center’s mission to preserve the products of NSF-funded science in the Arctic, including the data, metadata, software, documents, and findings that were generated as part of the research. The Arctic Data Center enables scientists to review, replicate, and synthesize products of prior research efforts — an essential feature of science. A strong focus of the Arctic Data Center, then, is enhancing the ability for individuals (and computers!) to find, interpret, and re-use data archived in the repository.
Wilkinson et al. described why preservation of scientific data is critical and provided some guidelines for maximizing the value of archived scientific data. The authors proposed four foundational principles for better stewardship of scientific data — that the data should be Findable, Accessible, Interoperable, and Reusable (FAIR). While not explicitly mentioned as such, examples of FAIR data repositories mentioned in the Wilkinson et al. paper prominently referenced Semantic Web technologies, built using W3C recommendations for describing and sharing distributed data. This brief article describes how the Arctic Data Center’s search system is using Semantic Web technologies to make data FAIR’er. By implementing semantic technologies, the holdings of the Arctic Data Center, and other web-accessible data repositories adopting similar approaches, become more discoverable, reusable, and interoperable.
User Interfaces for Semantic Search
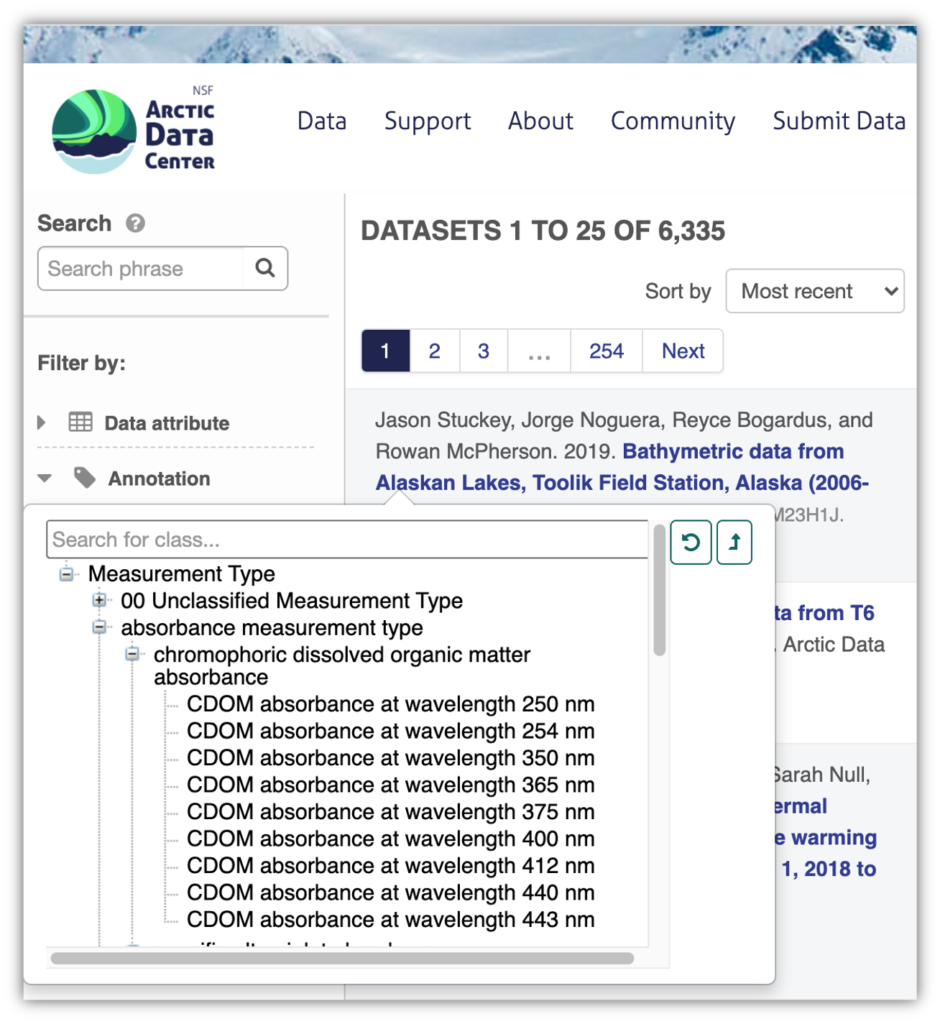
The Arctic Data Center currently provides semantic search features for measurements, i.e. attributes of data objects. Our initial focus has been on increasing the capability to find measurements of interest in tabular and worksheet data, where attributes are conventionally presented in columns, and are often also called parameters or variables. Semantic search in the Arctic Data Center is initiated by using the “Annotation” choice on the left search sidebar (Fig. 1). Semantically annotated searches are currently limited to measurements, as indicated by the “Measurement Type” entry in the search pop-up box, which depicts the standard “+/-” sign next to it to indicate that its contents can be expanded to reveal the measurements described in the ECSO ontology. This interface is directly interacting with the ECSO ontology to produce a hierarchical list of measurement types that may be annotated to datasets within the repository.
There are two ways to search for measurements. First, there is a “browse mode”, which enables you to scroll through the class hierarchy, expanding subclasses where indicated by a “+” sign, enabling you to rapidly gain an overview of the types of measurements available for annotation, and allowing one to “drill down” to more specialized measurements, such as is shown for CDOM absorbance at a specific wavelength (Fig 1). The display does not yet indicate the number of datasets that are annotated to those terms, though we anticipate this will be a future enhancement.
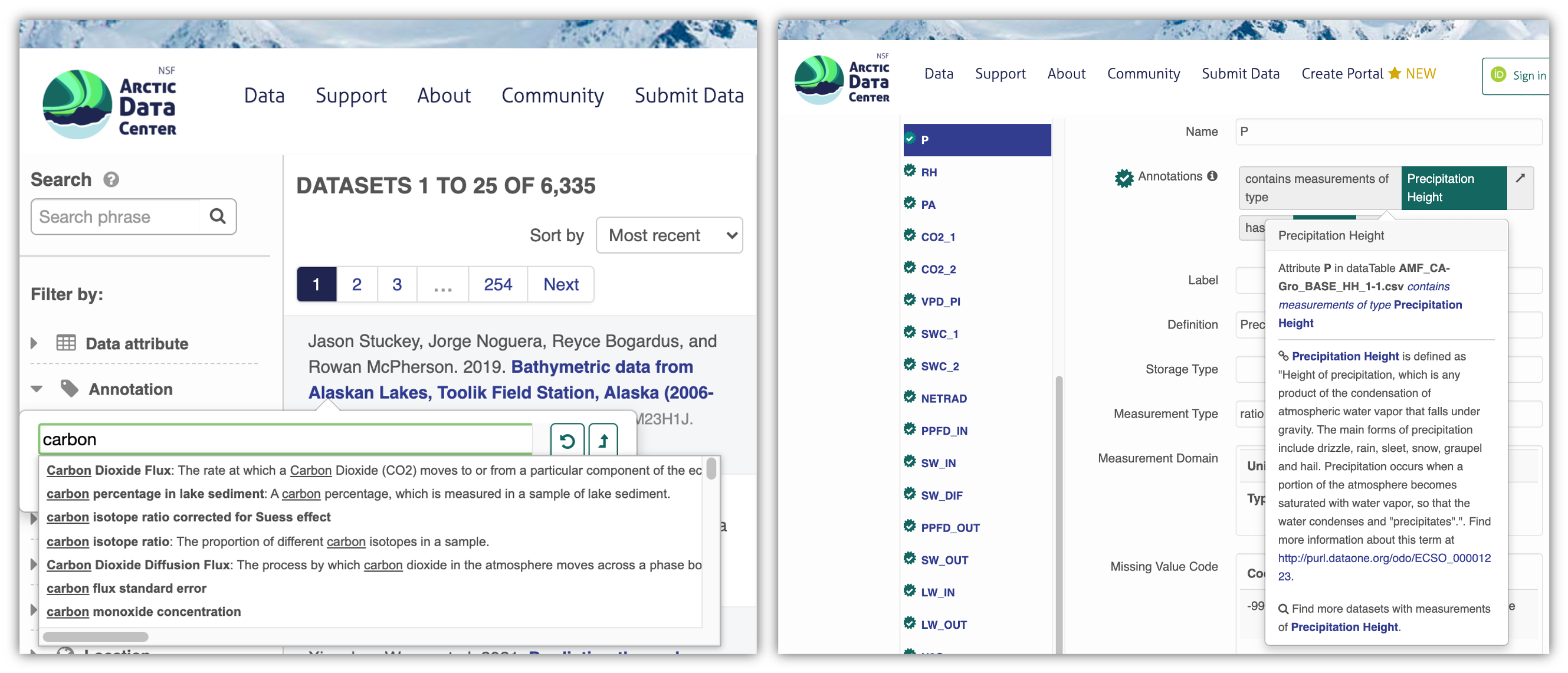
A second search method involves semantically searching for attributes by typing out the desired term(s) (Fig. 2). In this case, the ECSO ontology is assisting by doing an “autofill” search that not only matches the strings being typed, but also includes potential synonyms. For example, searching for Carbon Dioxide measurements would also find “CO2” measurements. Other features available in the Annotation search include resetting your search to the “top” of the Measurement Type hierarchy, or “moving up” the hierarchy to a parent class, which, e.g. for “Carbon Dioxide flux” would be “Carbon Flux”.
The Semantic Search system provides further benefits when reviewing the data for potential relevance and re-use. Once one has selected a data item of interest, and is examining it in detail, any semantically annotated measurements for that data item are indicated by a green checkmark in the Attribute Information display (left vertical pane; Fig. 6). In the example depicted, the researcher labeled their column of data as “P”, described in the EML metadata definition field simply as “Precipitation”. However, “Precipitation” is a measurement that can be interpreted in multiple ways: it could be an accumulation of rain, snow, hail or other accumulations on the ground of condensed water falling from the sky. Aside from its form, “Precipitation” can also be measured in different ways, e.g. as a volumetric amount, a height or depth, or a rate (intensity). Measurements of these various forms would not necessarily be comparable with each other, and a researcher can benefit from greater clarification among these types. A semantic annotation clarifies in this case that attribute “P” in the data table described in Fig. 3, the measurement is indeed of a “PrecipitationHeight”. Furthermore, at the bottom of the Annotation Information Box, a link is provided to other datasets in the Arctic Data Center that also contain this type of measurement.
What is “Semantics”?
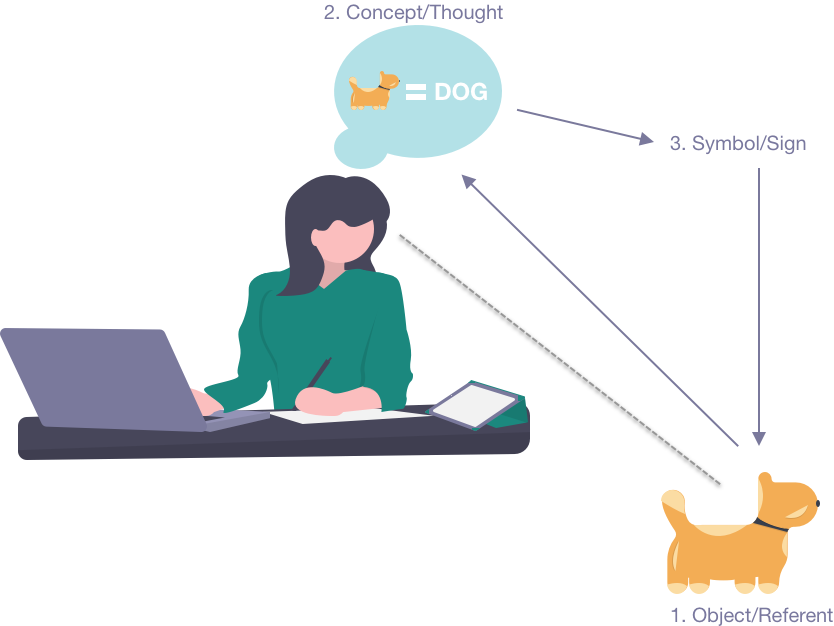
In a broad sense, semantics pertains to the study of meaning. Humans use language, signs, and symbols as a means to communicate about some intended concept, idea, or object. The letters “D”, “O”, and “G”, for example, when combined together comprise a word, or in semantics what we call a term— that is intended to convey some concept or intention of meaning. The term “DOG” is one symbolic way to communicate or represent the concept of a “dog” (Fig. 4). We use signs or symbols (not differentiated here), like the word “DOG”, as well as pictorial or auditory means, to represent and communicate concepts or thoughts, that are representations of actual or imagined objects or phenomena (also called “referents”). This relationship among thoughts, symbols, and their referents, is often called the “triangle of meaning” (Fig. 4).
a
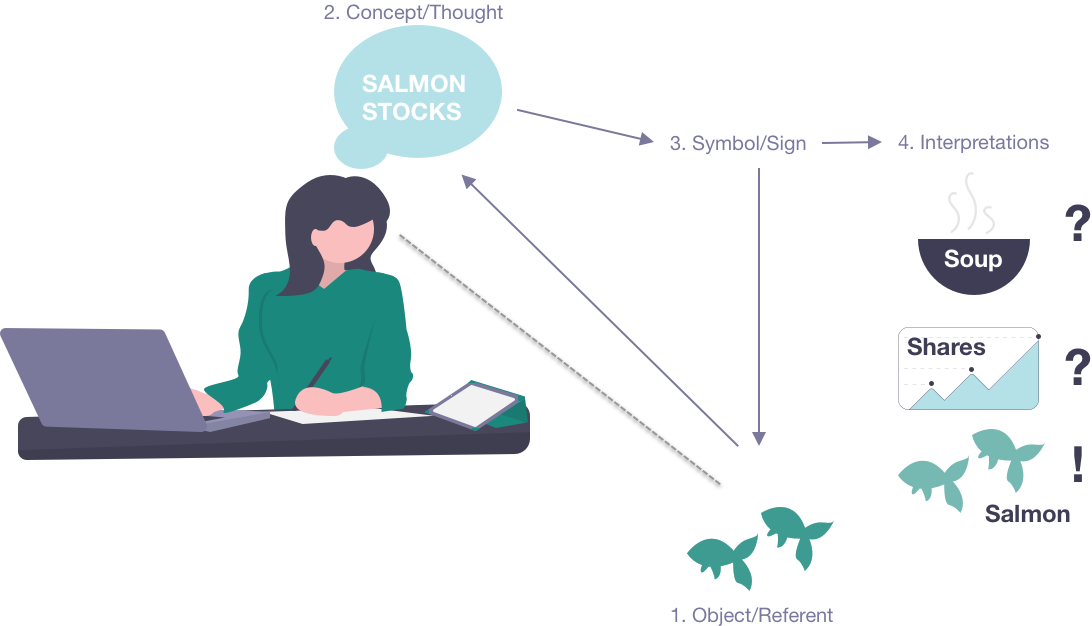
When a scientist is searching for data over the Web, they will type the word/phrase that they believe represents the relevant concepts into the search field of some application, e.g. Google, or a specialized Web interface. However, words can often be ambiguous, especially when they lack strong context. For example, if you are a salmon researcher searching for data about “salmon stocks”, you may not be interested in data about soup bases or fish farm companies, but rather data about populations of wild salmon (Fig. 5). Similarly, if you are a researcher investigating forest primary productivity, you might search for “litter accumulation” seeking data about fallen leaves rather than trash build-up on beaches. The problem in both cases is that computer-based search systems are simply processing sets of strings or terms — sequences of letters, numbers, and spaces — remaining ignorant about the specific underlying concepts that are the intended referents of those strings. This leads to lower search precision, resulting in receiving extraneous and irrelevant results, as well as lower search recall – i.e. not finding all of the potential items of interest. What is needed are mechanisms to clarify the concepts intended by the terms, as well as to enrich the context within which a search term is being used.
The semantic approaches adopted by the Arctic Data Center attempt to address these search challenges through implementation of technologies that adhere to W3C recommendations for the Semantic Web. The advantages are primarily two-fold. First, through assignment of a unique HTTP URI to each term that is linked to a dictionary style definition — thus, clarifying the intended meaning behind a string. The dictionary analogue here is referring to a formal ontology that is more like a turbo-charged dictionary: a controlled vocabulary that can contain compound concepts such as “net primary productivity” or “carbon dioxide flux”, along with their definitions and descriptions, and web links that can rigorously inter-relate these concepts with other concepts. For example, an Ontology can clarify that “carbon dioxide flux” involves the chemical compound “carbon dioxide” (that might also be called “CO2”), and is a measure of its “flux” (a measure of flow; Fig. 6).
Second, ontologies built using the W3C recommended RDF data model and OWL language enable standard ways to interoperably represent resources (documents, data, etc.) over the Web due to their having a common, formal logical structure. This formal structure is very unlike two documents or datasets that may be about the exact same resources or measurements, yet could represent those resources and measurements using different terminologies. The Arctic Data Center is using the Ecosystems Ontology (ECSO) to describe the measurements associated with datasets in the repository while maintaining close compatibility with the Environment Ontology (EnvO) that semantically describes a huge number of relevant environmental phenomena and features that can be measured (Buttigieg et al. 2016).
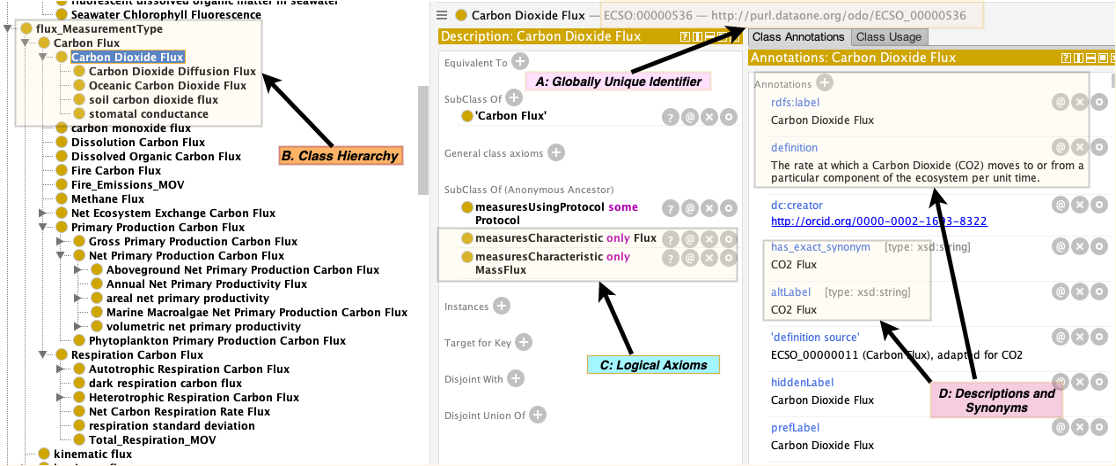
ECSO provides a web-accessible way to clarify the usages of terms, as each term has its own unique Identifier (HTTP URI), that dereferences (what happens when you enter the HTTP URI into a web browser) to “useful information”. Figure 6 depicts a view of the ECSO ontology using Protege software, but you can enter “purl.dataone.org/odo/ECSO_00000536” into any web browser and gain a similar view of ECSO Ontology. In a grammatical sense, ontologies can assist with differentiating term meanings in several useful ways:
- Homonyms (words spelled the same but with different meanings, as in the case of “salmon stocks” shown in Fig. 5)
- Synonyms (different words that represent the same concept, as shown in Fig. 3 for equating “carbon dioxide flux” with “CO2 flux”)
- Leveraging any hierarchical arrangement of terms, such that a query about “carbon flux” would also include any references to “stomatal conductance”, because the latter is a type (subclass) of carbon flux even though the words “carbon” or “flux” do not appear in it (Fig. 6).
Semantic Annotation: linking data and other resources to terms in Ontologies
How exactly does the ECSO ontology assist with finding, interpreting and reusing data? This is accomplished through “semantic annotation”, which involves associating a digital object, such as a web-accessible dataset or a column in a worksheet, with an annotation describing the type of information which that dataset or column contains. The annotation becomes semantic if it is not simply some free-form added note or metadata, but rather is a pointer to a term formally described in an ontology.
For example, if a data table contains a variable called “litter”, it becomes much clearer what is being measured if there is a reference to some widely-accessible, external, and credible source that specifies what is meant by “litter” in this context. One might indicate that the variable is described by the Merriam-Webster dictionary entry for “litter”, noun definition 4.a. But, even this is somewhat ambiguous without direct access to what that definition might be, even if we could cite the exact edition or ISBN number of the dictionary to clarify. We still need to locate that exact volume, or hope to access it through the Web, to read and verify the intended meaning of “litter”. Ideally, one has a URL (www.merriam-webster.com/dictionary/litter, accessed on 12DEC2020), that contains the intended definition, but there is still the needed additional information that only noun definition 4.a in that page is the correct one, such as purl.obolibrary.org/obo/ENVO_03500005. Specific URI’s that exactly identify and locate the definition and description of the annotated term stored in well-constructed ontologies represent an excellent solution for making the intended meaning of a term crystal clear.
Another distinct advantage of annotating data to terms/concepts in ontologies that data interoperability increases when ontologies are constructed using standardized machine-actionable representations recommended by the W3C. For example, the dataset doi:10.18739/A28911R0D in the Arctic Data Center has a table containing the attribute “cond_mmol_m-2_s-1” annotated to this ECSO term: purl.dataone.org/odo/ECSO_00003084. This URI can be dereferenced to clarify that attribute’s contents, but it’s doubly useful because it is available for the annotation of other digital resources, thereby serving as a common “online” reference that facilitates shared interpretation across repositories and researchers. Such shared semantics among resources cannot otherwise be inferred without detailed and essentially identical metadata describing the shared attributes, especially if these are from distinct projects or repositories. This approach is what drives the vision of the Semantic Web.
There are a number of ways in which semantic annotations can be applied to digital objects. Datasets archived in the Arctic Data Center are described using Ecological Metadata Language (EML), an XML-based schema, and there is documentation describing how semantic annotations can specifically be added to EML documents.
The essence of a semantic annotation, however, is simple:<this Digital Data Resource> <has Annotation> <term identifier in an Ontology>
The above “statement” conforms to the basic structure of the RDF data model, a triple. The resource to be annotated is called the Subject; the annotation, called the Predicate, describes the nature of the association; and the third item, the Object, provides the term that enriches understanding about the Subject. We could make statements such as:<Dataset XYZ> <is Collected by> <person Jane Doe><Variable “cond_mmol_m-2_s-1> <contains Measurements of> <CO2 flux>
Formally, taken together, these three components together comprise an RDF triple with a Subject, Predicate, and Object – each with unique identifiers expressed as HTTP URI’s. These URI’s can all be dereferenced with a web browser. In this way, useful information is provided about that digital resource: minimally in the form of a descriptive label, but often with an extended description, and additional information as well.
The following semantic annotation triple describes a dataset in the Arctic Data Center:<https://arcticdata.io/catalog/view/doi%3A10.18739%2FA2V97ZS50><https://www.w3.org/TR/prov-o/#influenced><http://purl.dataone.org/odo/ARCRC_00000002>
… but when viewed on the Web, is presented in a more human-readable form–The Dataset DOI:10.18739/A2V97ZS50 influenced “The Tundra Greenness Indicator”.
This example uses the predicate “influenced” from the W3C Provenance Ontology, PROV-O, which here indicates that the subject dataset helped inform (“influenced”) “The Tundra Greenness Indicator”, which is one of the essays included in NOAA’s 2020 Arctic Report Card.
Summary
The Arctic Data Center’s Semantic Search framework assists users in finding, interpreting and re-using data collected by researchers working in the Arctic. It helps resolve ambiguities arising from search terms that have homonyms or synonyms, as well as search terms that may have more specific “narrower types” or subclasses. This is achieved by matching “strings” typed into a semantic search field with an associated term in a Web-accessible, “rich vocabulary” (ontology) that is expressed in the standard W3C recommended machine-interpretable languages of RDF and OWL. Features of a dataset, such as the measurements it contains, are linked to terms from ontologies via annotations. The annotations, as well as the terms in the ontologies, are identified by unique and persistent HTTP URLs (or more formally, HTTP IRIs– Web “locators” that both “identify” and “name” a resource). Finally, the semantically-enhanced Web-based User Interface enables both researcher and automated machine-based access to the annotated data, providing for more efficient and effective discovery and interpretation of resources preserved in the Arctic Data Center.
While the Arctic Data Center’s Semantic Search system currently only operates on measurements, it will soon provide tools for semantic annotation and search at the data table and dataset (“package”) levels. For example, datasets may be annotated as to what biome the data were collected from (e.g. “alpine tundra biome”), or what environmental material was under investigation (“soil: alisol”), or what objects (“polar bear”) might appear in an image. Currently the process of creating Semantic Annotations requires some technical proficiency, due to the intricacies of the EML metadata that is used at the Arctic Data Center [6]. Soon, however, the Arctic Data Center will launch a “Semantic Annotation Editor” that will enable researchers to select terms from an ontology, and directly apply annotations to their data, thereby facilitating discovery and interpretation for themselves and others into the future.
A primary motivation for preserving data in the Arctic Data Center is to enable researchers to re-use those data in the future– to validate and replicate past results, but perhaps more importantly, to expand our understanding– synthesizing past data with new or additional data, re-analyzing these using different methods, or through testing of novel hypotheses with the data. The Arctic Data Center will continue to enhance its data holdings using the semantic approaches described here, that hold great promise for providing more powerful access to and interpretation of data within the Arctic Data Center, as well as for facilitating exchange of data and other information across repositories, e.g. with other Arctic-related data archives.
Written by Mark Schildhauer, co-PI